- Connected and Active Transformation
- The Aggregator transformation allows us to perform aggregate calculations, such as averages and sums.
- Aggregator transformation allows us to perform calculations on groups.
Components of the Aggregator Transformation
1. Aggregate expression
2. Group by port
3. Sorted Input
4. Aggregate cache
1) Aggregate Expressions
- Entered in an output port.
- Can include non-aggregate expressions and conditional clauses.
The transformation language includes the following aggregate functions:
- AVG, COUNT, MAX, MIN, SUM
- FIRST, LAST
- MEDIAN, PERCENTILE, STDDEV, VARIANCE
Single Level Aggregate Function: MAX(SAL)
Nested Aggregate Function: MAX( COUNT( ITEM ))
Nested Aggregate Functions
- In Aggregator transformation, there can be multiple single level functions or multiple nested functions.
- An Aggregator transformation cannot have both types of functions together.
- MAX( COUNT( ITEM )) is correct.
- MIN(MAX( COUNT( ITEM ))) is not correct. It can also include one aggregate function nested within another aggregate function
Conditional Clauses
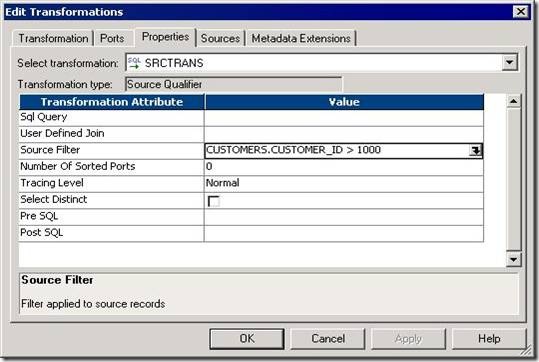
We can use conditional clauses in the aggregate expression to reduce the number of rows used in the aggregation. The conditional clause can be any clause that evaluates to TRUE or FALSE.
- SUM( COMMISSION, COMMISSION > QUOTA )
Non-Aggregate Functions
We can also use non-aggregate functions in the aggregate expression.
- IIF( MAX( QUANTITY ) > 0, MAX( QUANTITY ), 0))
2) Group By Ports
- Indicates how to create groups.
- When grouping data, the Aggregator transformation outputs the last row of each group unless otherwise specified.
The Aggregator transformation allows us to define groups for aggregations, rather than performing the aggregation across all input data.
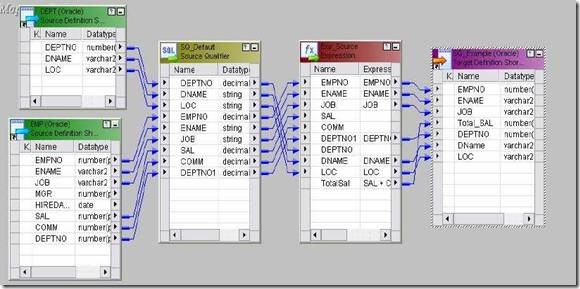
For example, we can find Maximum Salary for every Department.
- In Aggregator Transformation, Open Ports tab and select Group By as needed.
3) Using Sorted Input
- Use to improve session performance.
- To use sorted input, we must pass data to the Aggregator transformation sorted by group by port, in ascending or descending order.
- When we use this option, we tell Aggregator that data coming to it is already sorted.
- We check the Sorted Input Option in Properties Tab of the transformation.
- If the option is checked but we are not passing sorted data to the transformation, then the session fails.
4) Aggregator Caches
- The Power Center Server stores data in the aggregate cache until it completes Aggregate calculations.
- It stores group values in an index cache and row data in the data cache. If the Power Center Server requires more space, it stores overflow values in cache files.
Note: The Power Center Server uses memory to process an Aggregator transformation with sorted ports. It does not use cache memory. We do not need to configure cache memory for Aggregator transformations that use sorted ports.
1) Aggregator Index Cache:
The index cache holds group information from the group by ports. If we are using Group By on DEPTNO, then this cache stores values 10, 20, 30 etc.
- All Group By Columns are in AGGREGATOR INDEX CACHE. Ex. DEPTNO
2) Aggregator Data Cache:
DATA CACHE is generally larger than the AGGREGATOR INDEX CACHE.
Columns in Data Cache:
- Variable ports if any
- Non group by input/output ports.
- Non group by input ports used in non-aggregate output expression.
- Port containing aggregate function

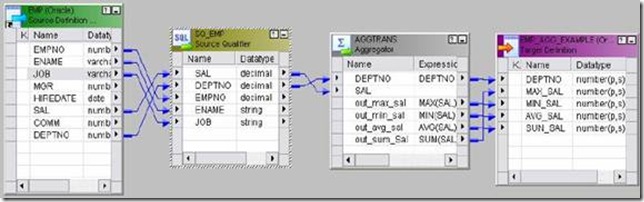
1) Example: To calculate MAX, MIN, AVG and SUM of salary of EMP table.
- EMP will be source table.
- Create a target table EMP_AGG_EXAMPLE in target designer. Table should contain DEPTNO, MAX_SAL, MIN_SAL, AVG_SAL and SUM_SAL
- Create the shortcuts in your folder.
Creating Mapping:
1. Open folder where we want to create the mapping.
2. Click Tools -> Mapping Designer.
3. Click Mapping-> Create-> Give mapping name. Ex: m_agg_example
4. Drag EMP from source in mapping.
5. Click Transformation -> Create -> Select AGGREGATOR from list. Give name and click Create. Now click done.
6. Pass SAL and DEPTNO only from SQ_EMP to AGGREGATOR Transformation.
7. Edit AGGREGATOR Transformation. Go to Ports Tab
8. Create 4 output ports: OUT_MAX_SAL, OUT_MIN_SAL, OUT_AVG_SAL,
OUT_SUM_SAL
9. Open Expression Editor one by one for all output ports and give the
calculations. Ex: MAX(SAL), MIN(SAL), AVG(SAL),SUM(SAL)
10. Click Apply -> Ok.
11. Drag target table now.
12. Connect the output ports from Rank to target table.
13. Click Mapping -> Validate
14. Repository -> Save
- Create Session and Workflow as described earlier. Run the Workflow and see the data in target table.
- Make sure to give connection information for all tables.